1. rust宏的简介
rust的宏系统按照定义的方式可分为两类:
声明宏(Declarative Macro)过程宏(Procedural Macro)
1.1 声明宏
声明宏是通过macro_rules!声明定义的宏,其具备以下特点:
- 基于TokenStream匹配的方式,在语法解析阶段对宏代码进行替换、展开;
- 由宏解析器(Macro Parser)进行进行解析,其他代码则有通用解析器(Normal Parser)进行解析。
rust声明宏的基本原理为匹配词条流进行替换,与c/c++中宏的文本替代(发生在词条提取阶段)不同,使用起来更加灵活自由。
1.2 过程宏
使用声明宏可以实现类似函数一样被调用的宏,但是也局限于代码自动生成的场景,对于需要语法扩展的场景用声明宏无法满足。比如为现有结构体自动生成特定的实现代码,或者对代码进行检查。在过程宏出现之前,开发者可以通过Ruts编译器的插件机制来满足语法扩展的诸多需求,但这些插件机制并不稳定,暂时只能在Nightly版本的Rust中使用。
下图展示了过程宏的工作机制
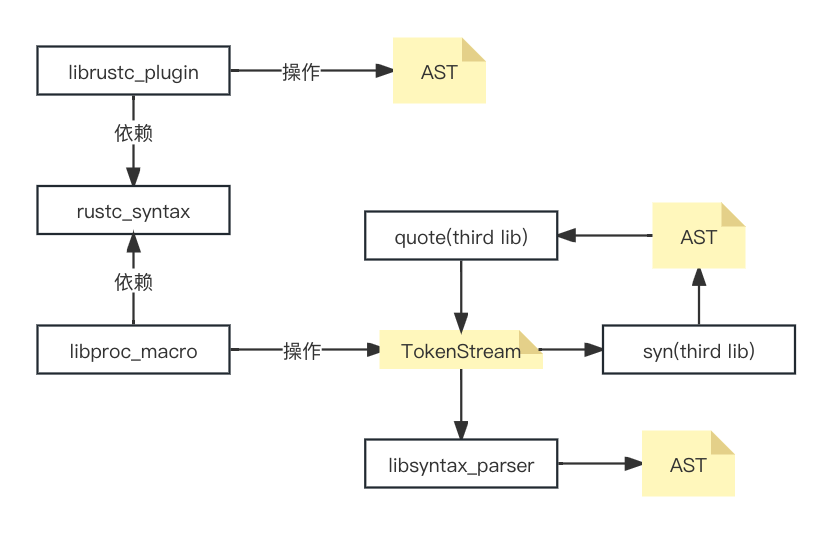
PS : Rust编译器插件机制由内置的librustc_plugin包提供,他通过直接操作AST来达成目的,因此,它依赖于内置的libsyntax包,该包中定义了词法分析、语法分析、操作语法树相关的各种操作。但由于Rust语言正处于上升发展期,还有许多工作要做,将来Rust的AST结构难免发生变化。如果将插件机制与AST结构偶合起来,会导致程序可可维护性大大降低。
过程宏建立在词条流(TokenStream)的基础上,开发者可以通过借助过程宏输入词条流,对代码进行修改或者替换,最后将修改后的词条流输出,交给语法分析器处理。
1.3 宏的属性
在Rust中,宏可以使用多个属性来指定其行为和特性。以下是一些常见的宏属性:
- #[macro_export]:将宏标记为可公开的,允许其他crate引用和使用该宏。
- #[macro_use]:告诉编译器在当前crate中启用宏的导入。这使得在使用该宏时无需使用完全限定路径。
- #[proc_macro]:将宏标记为过程宏。过程宏是一种特殊类型的宏,用于在编译时生成代码。
- #[proc_macro_attribute]:将宏标记为过程宏属性。过程宏属性是一种特殊类型的宏,用于为函数、结构体或其他项添加附加的属性或行为。
- #[proc_macro_derive]:将宏标记为过程宏派生。过程宏派生是一种特殊类型的宏,用于自动生成实现特定trait的代码。
2. 声明宏
声明宏中可以捕获的类型列表如下:
item代表语言项,就是组成一个Rust包的基本单位,比如模块、声明、函数定义、类型定义、结构体定义、impl实现等;block代表代码块,由花括号限定的代码;stmt代表以分号结尾的语句;expr代表表达式,会生成具体的值;pat指代模式;ty表示类型;ident代指标识符;path代指路径,比如:std::collections等;meta元信息,表示包含在#[…]或#![…]属性内的信息 ;ttTokeTree的缩写,代表词条树;vis指代可见性,比如pub;lifetime指代声明周期参数
在写声明宏时,需要注意以上捕获类型的匹配范围。
2.1 环境搭建
进行如下操作:
cargo new macro_test --lib
# 在生成的Cargo.toml文件[dependencies]下,增加如下内容
syn = "2.0"
quote = "1.0.33"
serde = {version = "1.0.188", features = ["derive"]}
serde_json = "1.0.107"
# 在src下新建文件declarative_macro.rs2.1 声明宏入门
在delcarative_macro.rs文件中输入一下代码:
#[macro_export]
macro_rules! init_type_value {
($type:ty => $value:expr) => {{
let mut _x: $type = $value;
_x
}};
}首先,第一行代码#[macro_export]是该宏的属性,将宏标记为可公开的,允许其他crate使用。macro_rules! 则是定义一个声明宏的固定语法,我们重点关注的是宏的内容:也即匹配方式和内部替换的实现。
宏定义的通用模式如下:
($lhs:tt) => ($rhs:tt);+也即,当宏解析器遇到macro_rules!定义的宏时,他会使用以上模式来解析宏,将宏定义中火箭符号左右两侧都解析为tt(即词条树)。然后,宏解析器将左右两侧的词条树保存起来当做宏调用的匹配器。结尾的“+”代表该模式可以是一个或者多个。
很显然,在2.1的例子中,我们的宏只定义了一个模式,该模式解析如下:
($lhs:tt) => ($rhs:tt);
lhs = ($type:ty => $value:expr)
rhs = {
let mut _x: $type = $value;
_x
}那这样结构就十分明显了,该宏接受一个与lhs匹配的代码,然后替换生成rhs中的代码。lhs中的匹配规则是 ty => expr, 也即左侧输入类型,右侧输入值;然后宏中会根据输入的类型和值返回一个变量(转移所有权的返回)。那我们可以使用这个宏了:
# 在src/lib.rs文件中添加如下代码
mod declarative_macro;
use declarative_macro::*;
mod tests{
use super::*;
#[test]
fn it_works(){
let x = init_type_value!(i32 => 1);
println!("x = i32 => 1 = {}", x);
}
}运行,得到以下结果:
x = i32 => 1 = 1这里需要注意的是,在Rust宏中,如果您要声明新的变量,通常需要将其包含在一对大括号中。这是因为在宏展开期间,Rust编译器会将宏中的所有代码视为单个表达式。如果您在宏中声明了一个新的变量,并且该变量不在表达式中使用,编译器会将其视为未使用的变量,并产生一个警告。
2.2 宏的重复匹配技巧
我们现在要定义一个具备以下功能的宏:
- 能够按照两种模式生成一个hashmap;
- 模式一:按照 “key => value”键值对的方式生成;
- 模式二:只输入key,键值默认为0;
那么根据需求,添加以下代码:
# src/declarative_macro.rs
#[macro_export]
macro_rules! hashmap {
($($key:expr => $value:expr),*) => {
{
let mut _map = ::std::collections::HashMap::new();
$(_map.insert($key, $value);)*
_map
}
};
($($key:expr),* $(,)*) => {
{
let mut _map = ::std::collections::HashMap::new();
$(_map.insert($key, 0);)*
_map
}
};
}依次介绍两个匹配模式:
(1)lhs为($($key:expr => $value:expr),*)
第一层匹配模式 $((pat),*),*代表重复(pat)模式任意次,而”,”则是两个模式之间的分隔符;
内层匹配模式就较为简单,$key:expr => $value:expr,简单接受形如”a => 1”,的参数,那么key就匹配到a上,value就匹配到1上。但在代码内部,需要加上$符号来使之生效。
rhs代码中,需要注意的是在插入键值对时,使用了如下代码:
$(_map.insert($key,$value);)*这代表这重复将生成匹配到的代码。
(2)($($key:expr),* $(,)*)
该匹配模式与第一个匹配模式并无大的差异,唯一的区别是内部多了一个匹配器$(,)*,很显然,该匹配器用于匹配一个或者多个逗号,这样在使用宏时,在最后一个表达式后添加逗号,也会匹配上。
测试:
let hashmap1 = hashmap! {1, 2, 3,};
dbg!(hashmap1);
let hashmap2 = hashmap! {
"a" => 1,
"b" => 2
};
dbg!(hashmap2);输出如下:
[src/lib.rs:12] hashmap1 = {
3: 0,
2: 0,
1: 0,
}
[src/lib.rs:18] hashmap2 = {
"b": 2,
"a": 1,
}这里如果使用如下代码,也即增加一个逗号,编译器就会提示匹配错误,这是因为在该匹配模式下,逗号为两个匹配表达式间的分隔符,如果使用了逗号,意味着逗号后面必须还要有一组待匹配的表达式。
let hashmap2 = hashmap! {
"a" => 1,
"b" => 2,
};2.3 宏的内部依赖宏
设想以下场景:当我们使用较多的键值对初始化hashmap时,如果在一开始就预留相应大小的空间,那么可能会出现扩容,这会带来性能损失,因此我们需要设计一个能够对匹配的模式进行计数的宏,设计思路如下:
借用空元祖的零成本抽象来计量匹配到的键数;
使用<[()]>::len()函数来计算长度;
首先写出这两个工具宏的代码,这样写就导致会额外生成两个对外公开的宏。
# src/declarative_macro.rs
#[macro_export]
macro_rules! to_unit {
($xx:tt) => {
()
};
}
#[macro_export]
macro_rules! count {
($($key:expr),*) => {
<[()]>::len(&([$(to_unit!($key)),*]))
};
}
#[macro_export]
macro_rules! hashmap_with_capacity {
($($key:expr => $value:expr),*) => {
{
let _cap = count!($($key),*);
let mut hashmap = ::std::collections::HashMap::with_capacity(_cap);
$(hashmap.insert($key, $value);)*
hashmap
}
};
}下面我们尝试将这两个宏作为内部宏来调用:
#[macro_export]
macro_rules! hashmap_with_capacity_ {
// 内部宏,需要写在真正的匹配规则前
(@to_unit_ $key:expr) => (());
(@count_ $($key:expr),*) => (<[()]>::len(&[$(@to_unit_ $key),*]));
($($key:expr => $value:expr),*) => {
{
let _cap = count!($($key),*);
let mut hashmap = ::std::collections::HashMap::with_capacity(_cap);
$(hashmap.insert($key, $value);)*
hashmap
}
};
}可以看出,内部宏在定义和使用时,需要在lhs左端加上”@”符号,这是一种惯用方法。内部宏是一种用于在宏展开期间执行某些操作的宏。与常规宏不同,内部宏不会被导出到外部作用域中,而是只能在当前宏定义中使用。
2.4 调试宏的方法
rustc提供了一些工具来调试宏,其中,最有用之一的是trace_macros!。它会指示编译器,在每一个宏调用被展开之前将其转印出来。使用步骤如下:
- 在定义宏的文件开头加上
#![feature(trace_macros)],启用跟踪宏展开的功能 - 在使用宏的函数开头,加上
trace_macros!(true); - 在函数中使用宏,然后将鼠标指针放在宏语句上,就可以看到展开后的宏
需要先将编译器版本换为nightly才可启动这一功能:
# 安装nightly版本编译器
rustup install nightly
# 切换到night版本编译器
rustup default nightly需要注意的是,不能再lib.rs文件的测试文件中使用,因为trace_macros是一个不稳定的特性。
fn main() {
trace_macros!(true);
let hashmap1 = hashmap! {1, 2, 3,};
}展开后的结果为:
trace_macro
expanding `hashmap! { 1, 2, 3, }`
to `{
let mut _map = :: std :: collections :: HashMap :: new() ;
_map.insert(1, 0) ; _map.insert(2, 0) ; _map.insert(3, 0) ; _map
}`3. 过程宏
目前,使用过程宏可以实现三种类型的宏:
自定义派生属性自定义属性Bang宏
下面通过例子讲解,这几种宏分别是什么,实现了怎样的功能。这里需要注意,新建一个工程,并将lib包的类型设置为proc_macro,具体的做法如下:
cargo new proc_macro_test --lib
# 在Cargo.toml文件中做如下修改
[lib]
proc_macro = true